
Native PDF Structure
Intelligence for LLMs
Extract structured text, tables, and images from PDFs with automatic structure preservation. Optimized for RAG pipelines and Large Language Models.
MosttoolsrenderPDFsintoimages,thenguessthestructureback.PyMuPDF4LLMreadsthevectordatadirectly,preserving100%fidelity.
Compare Python-native performance against vision models
PyMuPDF4LLM processes PDFs 10x faster than alternatives. Extract text, tables, and structure at lightning speed, no GPUs, no cloud APIs, just pure Python performance.
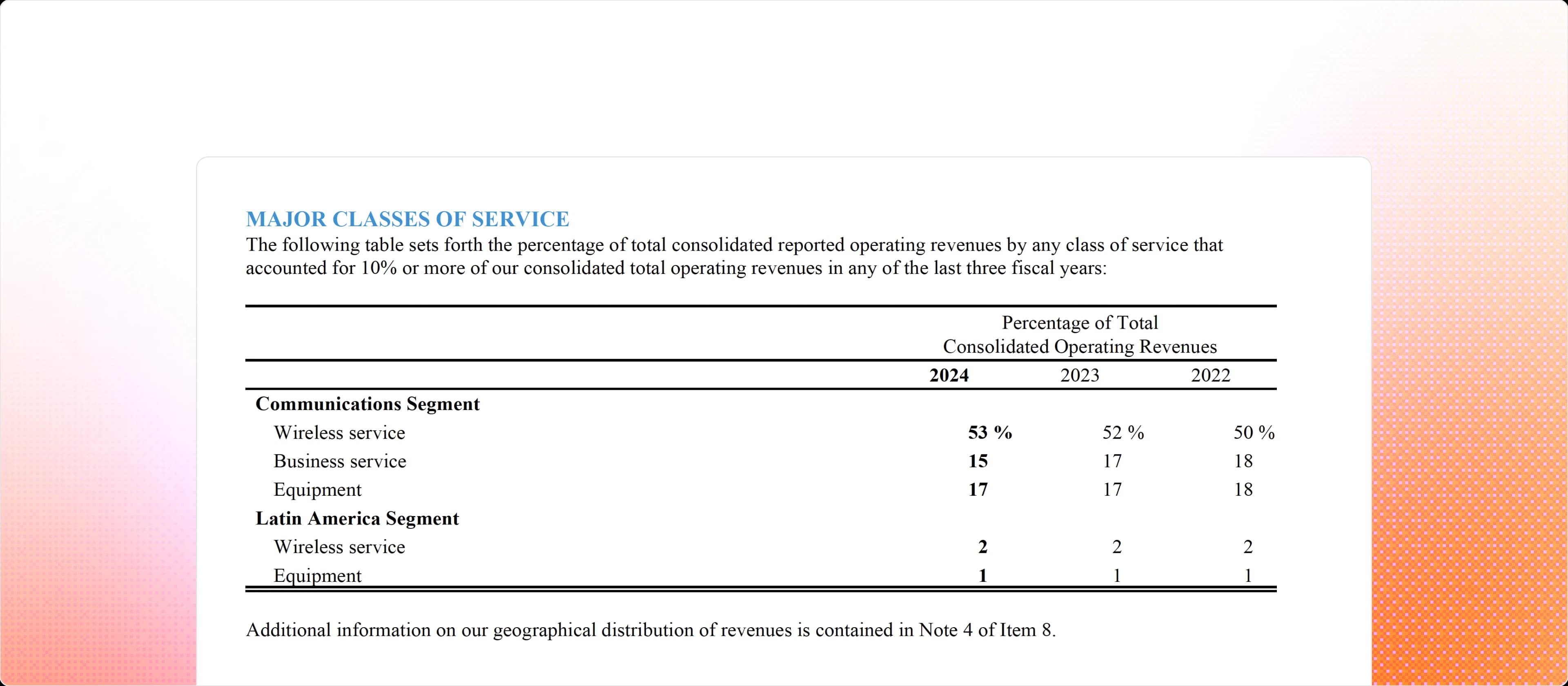
Why PyMuPDF4LLM?
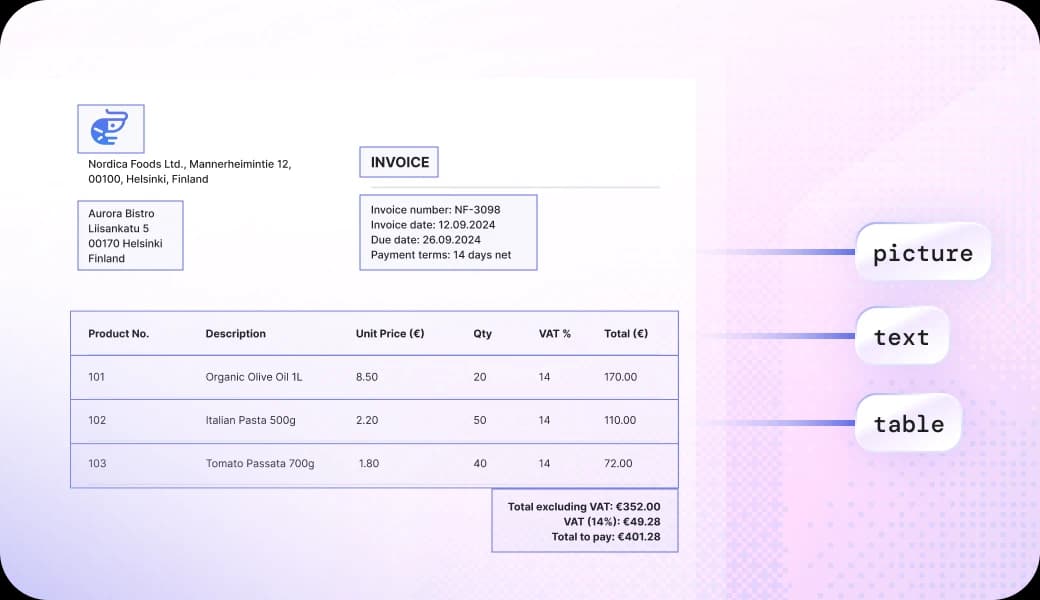
Reading the Document's DNA
We read PDF structure (fonts, spacing, positions, etc) directly, then use a Graph Neural Network to understand the patterns.

CPU Processing, GPU-Level Accuracy
While VLMs burn through expensive compute just to recognize titles and tables, our CPU-based approach handles all the structure extraction.

Built on Decades of PDF Knowledge
Decades of PDF expertise meeting real-world AI demands, engineered for modern workflows.
Try the PyMuPDF4LLM
Interactive Demo
10x faster than GPU-based solutions. Runs on any CPU. Upload your PDF and watch PyMuPDF4LLM extract clean, structured text in seconds—no signup required.

Enterprise Scalability
Starts with Better Data
PyMuPDF is built on open collaboration and always will be. Our code is freely available on GitHub under the AGPL license, welcoming contributions from developers worldwide. For projects requiring different terms, we also offer commercial licensing through Artifex.
Need Pro support
or Office/OCR?
Upgrade to PyMuPDF Pro to get support for Office formats, HWP documents and complete document manipulation with PyMuPDF4LLM.

Your Next Document Pipeline
Starts Here
Install PyMuPDF, extract your first document, and see why thousands of developers trust us for production document processing.