
PyMuPDFによるテキスト抽出 著者
ハラルド・リーダー(Harald Lieder)- 2022 年7月13日(水曜日)
PyMuPDFを使用したテキスト抽出
PyMuPDF:ただのテキスト抽出パッケージですか?
PDFドキュメントからテキストを抽出するためのオープンソースおよび商用のパッ ケージや製品は数多く存在します。
ではなぜPyMuPDFを見る価値があるのでしょうか?
この記事では、PyMuPDFが他のアプローチとどのように異なるのかを説明し、最初 のステップを示します。
PyMuPDFは...
- Artifexが所有および維持している製品です。オープンソースのフリーウェアライ センス(GNU AGPL 3.0)および商用ライセンスで利用できます。
- Pythonのプログラミングライブラリであり、CライブラリであるMuPDFに便利 なアクセスを提供します。MuPDFもArtifexが同じライセンスモデルで所有およ び維持しています。
- GitHub上にホームページがあり、PyPIからインストールできます。
- MuPDFの多くの機能をサポートしています。テキスト抽出はその数十ある他の機能の一つに過ぎません。
- テキスト抽出は、他の機能と同様に、優れたパフォーマンスと卓越したレンダリング品質で知られています。
- PDFドキュメントに限定されているわけではありません。他のパッケージとは異 なり、PyMuPDFのAPIはPDFの他にXPS、EPUB、HTMLなどのサポートされてい るすべてのドキュメントタイプに対して同じ方法で動作します。フリーウェアま たは商用を問わず、これが可能なパッケージは知られていません。
- TesseractのOCRエンジンを統合的にサポートしています。スクリプト内で、フ ルドキュメントページのOCR化が必要か、一部の部分のみのOCR化が必要かを動 的に決定し、Tesseractを呼び出してその出力を「通常の」テキストと一緒に処 理することができます。
テキストの抽出において何が問題になる可能性がありますか?
もしテキスト抽出ツールを使用したことがある場合、少なくとも以下のいくつかの 厄介な状況に遭遇したことがあるかもしれません:
- 正しい("自然な" / 予想される)読み取り順序ではないこと。
- サポートされていない文字や読み取り不可能な文字が表示されること。例えば、ここに ”The �ase �lass fo� P�MuPDF’s linkDest, ...” のような文字化けが表示されることがあります。
- 人間はページを読むことができるが、プログラムは何の出力も生成しないこと。
PyMuPDFは、これらの問題に対処するためのサポートを提供できます。
必要に応じて、基本的なプレーンテキストの抽出(1つのPythonステートメントだ けで可能)と、ページ上の各文字の位置、書き方の方向、色、フォントサイズ、 フォント名、フォントのプロパティなどに対する高度なアクセスの中から選択する ことができます。
出力形式は、プレーンテキスト、HTMLやSVGのような特殊な形式から、詳細な Python辞書(またはJSON文字列)まで、さまざまな形式があります。
PyMuPDFのテキスト抽出の使用方法
プレーンテキストの抽出:
他のPythonパッケージと同様に、まずPyMuPDFをインポートする必要があります。 これは、トップレベル名「fitz」の下で行われます。
In [1]: import fitz # import PyMuPDF
In [2]: doc = fitz.open("PyMuPDF.pdf") # open a supported document
In [3]: page = doc[0] # load the required page (0-based index)
In [4]: text = page.get_text() # extract plain text
In [5]: print(text) # process or print it:
PyMuPDF Documentation
Release 1.20.0
Artifex
Jun 20, 2022
In [6]:
シンプルな方法で作成されたドキュメントの場合、これだけでテキスト抽出が可能です。
PyMuPDFでは、すべてのドキュメントが ページのシーケンスでもあるため、 Pythonのシンタックスパワーを持つイテレータとして使用することができます。以 下のコードは、すべてのドキュメントページを抽出し、改ページ文字0XCでテキス トを連結します。
In [7]: all_text = ""
In [8]: for page in doc:
...: all_text += page.get_text() + chr(12)
In [10]: # or, with the even faster list comprehension:
In [11]: all_text = chr(12).join([page.get_text() for page in doc]) In [13]:
上記の方法は非常に高速です。AdobeのPDFマニュアル(756ページ、1,310ペー ジ)や、3,000ページ以上のPandasマニュアルなどの完全なドキュメントに対し て、実行時間は0.7秒から2秒未満になることが予想されます。
この方法は、pdftotext (Popplerの基本ライブラリであるXPDFのコンポーネント)よりも約3倍高速であり、pdfminerやPyPDF2などの一般的な純粋なPythonパッケージよりも30倍から45倍速いです!
もしドキュメント内のテキストが物理的に読み取り順序で保存されていない可能性 がある場合は、メソッドのsortパラメータを使用することで対処できます: page.get_text(sort=True)。これにより、ページのテキスト段落が「左上から右下」 の順序で並べられ、多くのドキュメントに対して満足のいく結果が得られるはずで す。
また、ページの特定の領域にテキストの抽出を制限することもできます。たとえ ば、ページが2列のレイアウトを持つ場合、それぞれの領域を表す2つの矩形を定義 し、対応するテキスト部分を別々に抽出することができます。
page_rect = page.rect # the full page rectangle
half_width = page_rect.width / 2 # half of the page width
left_rect = +page_rect # copy of page rectangle
left_rect.x1 = half_width # only left half
right_rect = +page_rect # copy of page rect
right_rect.x0 = half_width # only right half
# use those two rectangles as clip areas for extractions:
left_text = page.get_text(sort=True, clip=left_rect)
right_text = page.get_text(sort=True, clip=right_rect)
全ての詳細を含めてテキストを抽出する。
同じ方法は、抽出されたテキストとともに詳細な情報を提供することもできます。 例えば:
- 書き方の方向とモード(水平/垂直)
- 色(RGB)
- フォント名とフォントのプロパティ
- 位置情報(単一の文字、行、段落ごと)
- 画像
- 自動的なスペースの置換
- 自動的なハイフネーションの検出と処理
PyMuPDFのドキュメントPDFマニュアルのヘッダーページから、小さな例を選んで みましょう(こちらからダウンロードできます):
In [1]: import fitz
In [2]: doc = fitz.open("PyMuPDF.pdf")
In [3]: page = doc[0]
In [4]: all_infos = page.get_text("dict", sort=True)
In [7]: pprint(all_infos)
{'blocks': [{'bbox': (240.0, 88.94, 540.0, 388.94),
'bpc': 8,
'colorspace': 3,
'ext': 'png',
'height': 1200,
'image': b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x04\xb0'
<< ... omitted data ... >>,
'number': 0,
'size': 107663,
'transform': (300.0, 0.0, -0.0, 300.0, 240.0, 88.94),
'type': 1,
'width': 1200,
'xres': 96,
'yres': 96},
{'bbox': (236.90, 396.92, 540.0, 432.41),
'lines': [{'bbox': (236.90, 396.92, 540.0, 432.41),
'dir': (1.0, 0.0),
'spans': [{'ascender': 1.125,
'bbox': (236.90, 396.92, 540.0, 432.41),
'color': 0,
'descender': -0.307,
'flags': 20,
'font': 'TeXGyreHeros-Bold',
'origin': (236.90, 424.80),
'size': 24.79,
'text': 'PyMuPDF Documentation'}],
'wmode': 0}],
'number': 1,
'type': 0},
{'bbox': (422.28, 433.36, 540.0, 457.98),
'lines': [{'bbox': (422.28, 433.36, 540.0, 457.98),
'dir': (1.0, 0.0),
'spans': [{'ascender': 1.123,
'bbox': (422.28, 433.36, 540.0, 457.98),
'color': 0,
'descender': -0.307,
'flags': 22,
'font': 'TeXGyreHeros-BoldItalic',
'origin': (422.28, 452.7),
'size': 17.215,
'text': 'Release 1.20.0'}],
'wmode': 0}],
'number': 2,
'type': 0},
{'bbox': (485.57, 515.51, 540.0, 540.17),
'lines': [{'bbox': (485.57, 515.51, 540.0, 540.17),
'dir': (1.0, 0.0),
'spans': [{'ascender': 1.125,
'bbox': (485.57, 515.51, 540.0, 540.17),
'color': 0,
'descender': -0.307,
'flags': 20,
'font': 'TeXGyreHeros-Bold',
'origin': (485.57, 534.88),
'size': 17.22,
'text': 'Artifex'}],
'wmode': 0}],
'number': 3,
'type': 0},
{'bbox': (468.89, 652.26, 540.0, 669.38),
'lines': [{'bbox': (468.89, 652.26, 540.0, 669.38),
'dir': (1.0, 0.0),
'spans': [{'ascender': 1.125,
'bbox': (468.89, 652.26, 540.0, 669.38),
'color': 0,
'descender': -0.307,
'flags': 20,
'font': 'TeXGyreHeros-Bold',
'origin': (468.89,
665.71),
'size': 11.96,
'text': 'Jun 20, 2022'}],
'wmode': 0}],
'number': 4,
'type': 0}],
'height': 792.0,
'width': 612.0}
In [8]:
page.get_text() の上記の "dict" 出力オプションは、Pythonの多層辞書を返します。 絵は千語に値すると言いますので、この画像をご覧になることをお勧めします:
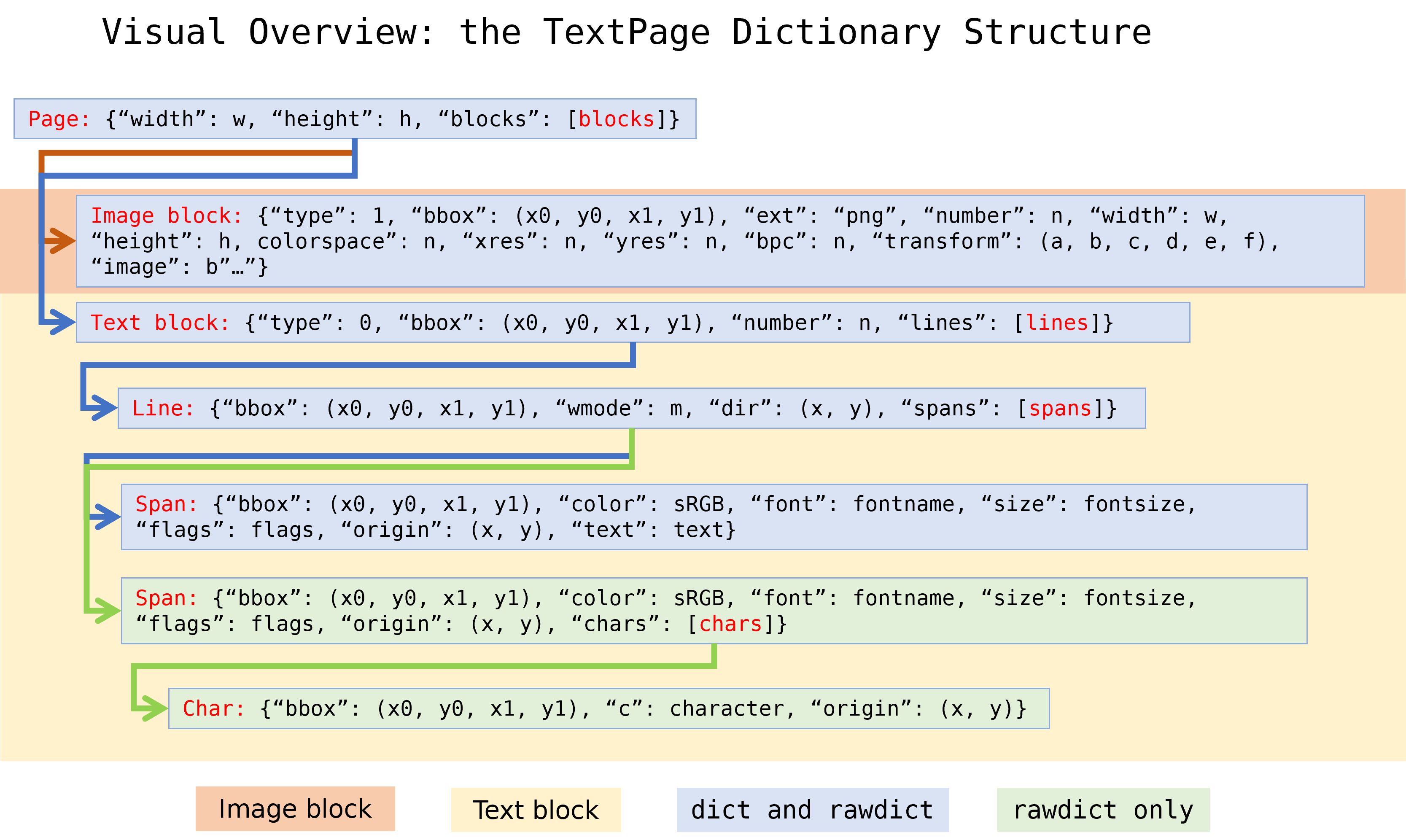
- 上位レベルは「block」の辞書であり、画像またはテキスト段落 を表します。す べての下位レベルの辞書と同様に、ブロックにはページ上の位置(「boundary box」=「bbox」)が含まれます。
- テキストブロック には「line」の辞書のリストが含まれています。
- bbox以外にも、「line」の辞書には書き方の方向(「dir」:タプル)、書き方 のモード(「wmode」:水平または垂直)、およびテキスト「span」の辞書の リストが含まれます。
- テキストスパン は、フォント、フォントサイズ、および色のプロパティが同じ である文字列です。テキストに複数のフォント属性や色がある場合、行には複数 のスパンがあります。
- bbox以外にも、スパンには挿入開始点(「origin」と呼ばれる)が含まれてお り、使用するフォントの基本的なプロパティ(フォントのアセンダー値やディセ ンダー値など)が報告されます。詳細は、この記事を参照してください。
上記の豊富な情報を利用することで、高い精度でページの外観を再現することが可 能です。これは、既存のPDFの選択されたフォントを置き換える ことができる、このスクリプトの例セットによって使用されています:
技術文書の中で「Courier」フォントの外観が気に入らないですか? これらのスクリプト を使って、「Ubuntu Mono」に置き換えてみてください!
特別な出力形式の抽出
上記で述べたように、メソッドの位置パラメータを使用して、他のテキスト出力形 式を要求することができます。次のようにして、HTMLページ(またはXHTMLや XMLなどの類似の形式)を作成し、インターネットブラウザで表示することができ ます。
text = page.get_text("html")
html_page = open("page-%i.html" % page.number, "w")
html_page.write(text)
html_page.close()
上記の「dict」形式の出力と同様に、HTML出力にはページ上の画像も含まれます。
テキスト抽出にPyMuPDFをモジュールとして使用する方法
多くの場合、スクリプトを書く手間を省くために、Pythonモジュールとしての PyMuPDFを使用して、コマンドラインでpython -m fitz gettext ... を使ってテキスト 抽出を行うことが役立ちます。
それは複数のパラメータによって影響を受けるテキストファイルを生成します。
利用可能な出力モードは3つあります:
fitz gettext -mode simple-page.get_text()の出力を生成します。fitz gettext -mode blocks-page.get_text(sort=True)の出力を生成します。fitz gettext -mode layout- 元のページレイアウトに似た出力を生成します。詳細 については、PyMuPDFのドキュメンテーションのこの部分をご覧ください。
他のパラメータを使用することで、ページ範囲、最小フォントサイズなどを選択す ることができます。
ダイナミックOCR
PDF文書形式の主な目的は、テキストや他のデータを 表示することです。
PDFからテキストを 抽出することは、常にうまくいくとは限りません。特定の要件 を満たす必要があります。
最も重要な要件は、文字の視覚的な外観(その "グリフ")を元のUnicodeに戻す データの利用可能性です。この情報("文字マップ"、CMAP)は、フォントに対して まったく与えられない場合がありますし、またはフォント内の特定の文字に対して与えられない場合もあります。
CMAPの欠如はテキストの抽出を防ぎます 。この障害を乗り越える唯一の方法は、 光学文字認識(OCR)を使用することです。
MuPDFとPyMuPDFはともにOCRツールであるTesseractをプログラムから呼び出す ことをサポートしています。このインターフェースの複数の可能な使用方法のう ち、次の状況を選択し、解決策を示します:
- 前提として、あるページのテキストには有効なUnicodeがないグリフが含まれているとしましょう。
- (Py-) MuPDFのテキスト抽出は、そのようなグリフごとに文字
chr(0xFFFD)を返します(U+FFFDは無効なUnicode値です)。 - エラーのあるUnicodeのテキストに遭遇するたびに、テキストの境界ボックスの一時的なイメージを作成し、Tesseractにテキストを認識させるようにします。
このアプローチの利点は、OCRが実際に必要な箇所でのみ使用されることです。こ の種の問題がないページでは、実行速度の低下や抽出品質の低下は発生しません。
このデモスクリプトをご覧ください。これは先程の手順に完全に従っています。テ キストの一部をOCRで認識する必要がある場合、それは以下のように報告されます (各�は1つのchr(0xFFFD)を表します):
before: 'binaries we generate – our decisions are ��u��t i�� i�to them. '
after: 'binaries we generate — our decisions are “burnt in” into them. '
まとめ
PyMuPDFの多くの機能について、ほんの一部分だけでも楽しんでいただけたことを 願っています。
テキスト処理についてだけでも、テキストの検索とハイライト、テキストの赤塗り を使ったテキストの操作など、さらに多くのことが語られるでしょう。
将来の記事でこれらのトピックの一部を取り上げる予定です。
PyMuPDFは大規模で機能豊富なドキュメント処理用のPythonパッケージです。卓越 したパフォーマンスと優れた描画品質に加えて、優れた ドキュメントが提供されて いることでも知られています。現在のPDFバージョンはレターフォーマットで420 ページ以上あり、そのうち70ページ以上がHow-To形式のレシピに充てられていま す。確かに価値のある読み物です。
もう一つの知識源はユーティリティリポジトリです。PDFを扱う際に何かを計画し ている場合は、おそらくそこにいくつかの例示スクリプトが見つかるでしょう。そ れがスタートの手助けとなるでしょう。
PyMuPDFに関する質問があれば、#pymupdf Discordチャンネルで開発者に連絡す ることができます。